J’ai été et je suis toujours convaincu qu’il est plus simple et efficace de faire du push par rapport à du pull pour le monitoring d’une infrastructure. Dans cet article, j’expliquerai pourquoi et parlerai de différents outils comme Riemann, Prometheus ou Vector.
Riemann
J’ai à une époque beaucoup contribué à Riemann. Cet outil de monitoring écrit par Kyle Kingsbury (Aphyr) n’a selon moi toujours aucun équivalent sur le marché du monitoring aujourd’hui. C’est plein de bonnes idées, c’est vraiment un outil où en tant qu’utilisateur (et puis en tant que contributeur) j’ai eu un effet "Wahou" en voyant comme ça marche.
Vous ne connaissez pas Riemann ? La documentation est un bon point d’entrée, mais voici un petit résumé.
Riemann est un outil de stream processing pour le monitoring. Vous pouvez y pousser toutes sortes d’événéments (métriques applicatives, systèmes, événements divers et variés…) et Riemann va pouvoir les transférer à des systèmes externes (comme Graphite, InfluxDB…), réaliser des calculs complexes (notamment sur des fenêtres de temps) et générer des alertes (et les envoyer à Pagerduty par exemple). Voici un event Riemann:
{:host "mcorbin.fr" ;; la source de la métrique
:service "ram-usage" ;; le service concerné
:ttl 60 ;; un TTL associé à la métrique pour certains usages interles
:tags {:environment "prod"} ;; des tags qui peut être ajoutés à la métrique
:time 1606854392183 ;; un timestamp
:metric 75 ;; la valeur de la métrique}
;; d'autres champs arbitraires peuvent être attachés à la métrique.
La configuration de Riemann est du code (Clojure), et sa configuration est 100 % testable unitairement. Voici un exemple:
(where (service "ram-usage")
(by [:host]
(fixed-time-window 60
(smap mean
influxdb))))
Ici, je filtre tous les événements ayant pour service ram-usage, je bufferise pour chaque :host (grâce à by) ces événements pendant 60 secondes, et je calcule ensuite la moyenne de ces événements (toujours par host). Cette moyenne est envoyée ensuite à InfluxDB.
Calculer la moyenne de la RAM n’est pas utile mais cela me permettait de donner un exemple simple.
Riemann est vraiment très (très) expressif, et surtout c’est du code donc extensible à l’infini (on peut écrire ses propres fonctions). Par exemple, je l’avais utilisé avec succès pour détecter des déséquilibres dans des partitions Kafka (en comparant les métriques de chaque partitions entre elles en temps réel).
De plus, tout est immuable dans Riemann. Un événement peut passer dans plusieurs "streams" sans problème, donc vous pouvez transférer l’événements original à un autre système tout en faisant des calculs complexes dessus dans des streams indépendants.
J’avais d’ailleurs réalisé une présentation sur cet outil (car il y a beaucoup d’autres trucs cools dans Riemann).
Riemann est toujours utilisé dans l’entreprise où je travaille aujourd’hui (bien que l’on transitionne sur Prometheus, j’en parlerai plus loin), mais l’outil a quand même quelques problèmes, notamment:
- Difficile de faire de la HA avec (il faut faire du sharding manuel). Mais bon, est ce que c’est mieux chez la concurrence ?
- Perte de l’état interne des streams en cas d’un reload (changement de configuration)
- Gestion des fenêtres de temps parfois un peu étrange (j’en parlerai plus loin)
- Quelques petits défauts notamment sur le steam
(by)(qui permet de créer plusieurs sous streams en fonction de clés d’un événement) qui n’était jamais GC (donc si vous avez beaucoup de cardinalité ça posait des problèmes).
Mais de manière générale, Riemann fonctionne, et c’est fou qu’un outil maintenu par la communauté soit allé aussi loin.
Mais pour aller plus loin et corriger ses défauts structurels il aurait besoin d’une réécriture "from scratch". C’est un projet qui mettrait au minimum plusieurs mois pour quelqu’un de motivé travaillant un peu tous les jours (et on sait que les estimations en informatique c’est pas fiable, donc ce serait beaucoup plus en réalité :D).
Mais reparlons du push et du pull.
Prometheus
Prometheus s’impose aujourd’hui comme un standard, qu’on le veuille ou non. L’outil a été pensé et conçu pour ne fonctionner qu’en mode "pull": les services à monitorer exposent les métriques via HTTP, et Prometheus va les chercher périodiquement. Selon la doc Prometheus, cela a plusieurs avantages:
Pulling over HTTP offers a number of advantages:
You can run your monitoring on your laptop when developing changes.
You can more easily tell if a target is down.
You can manually go to a target and inspect its health with a web browser.
Je ne suis d’accord avec aucun de ces affirmations.
Déjà, qu’une métrique soit exposée en HTTP ou poussée sur le réseau est un détail d’implémentation. Je pourrai très bien exposer mes métriques je sais pas trop où en dev et autre part en prod par exemple.
Ensuite, c’est vrai que Prometheus permet de détecter si une cible ne répond plus. C’est également possible de le faire avec du push en détectant une source n’ayant pas émis de données pendant X temps. Cela demande un peu de travail, mais ça se fait (et je l’ai fait dans certains projets).
Pour le troisième point, pareil, détail d’implémentation. Je pourrai avoir mes métriques exposées d’une façon ou une autre pour le debugging et les pousser quand même sur le réseau.
Par contre, voici selon moi les désavantages du pull:
-
Complexité réseau. En push, vous avez 1 règle de firewalling: de vos applications à votre truc qui stocke vos métrique (si c’est Kafka c’est encore mieux). En pull, si j’ai 10 applications qui exposent du Prometheus sur un serveur, j’ai 10 ports ouverts entre mon Prometheus et mon serveur. Et ça sur chaque serveur.
Vous allez me dire "c’est pas grave, moi j’automatise mon infra, ouvrir des ports c’est facile !". Si on veut, ça reste sujet à erreur. Notre job est déjà assez complexe pour ne pas avoir à se compliquer la vie. -
Si Prometheus ne pull plus pour une raison X ou Y, vos métriques sont perdues. En push, je peux avoir mon Kafka (par exemple) qui fait buffer et permet de "récupérer" mes métriques une fois un incident résolu.
-
Je pense que le push est plus simple à scale, et plus flexible. Dans une ancienne expérience on envoyait toutes nos métriques dans Kafka. N’importe qui pouvait brancher son consumer dessus et envoyer les métriques où il voulait, c’était super.
Quelqu’un veut tester InfluxDB ? Pas de problème. Vous décidez de partir sur Datadog finalement ? Allez, un nouveau consumer, et vous envoyez tout ça à l’extérieur. Bref, zéro couplage, le top.
Et enfin, je n’aime pas les DSL à la Prometheus. Avoir un DSL, OK, mais je veux pouvoir facilement l’étendre avec du code et avoir accès à un vrai langage de programmation. Sinon les queries deviennent des usines à gaz.
Je recommande Prometheus
Pourtant, j’ai encouragé le passage à Prometheus dans mon équipe. Pourquoi ? Pragmatisme.
Comme dit précédemment, Prometheus est partout. Si vous faites du Kubernetes par exemple, ne pas utiliser Prometheus c’est se tirer une balle dans le pied. Les intégrations sont là, et soyons honnête la solution fonctionne quand même.
Je ne l’aurai pas implémenté de cette façon si j’avais eu le choix, mais Prometheus est là, facile à installer, facile à brancher sur votre service de discovery préféré, et ça marche.
Mais les outils ne vivent pas pour toujours. Dans 2, 3, 5 ans ou plus de nouveaux outils apparaîtrons, et j’espère qu’on aura quelque chose de différent.
Mon outil idéal
Je reste convaincu que beaucoup d’idées de Riemann mériteraient d’être implémentées dans d’autres outils, avec quelques variations.
Il reste un soucis avec le stream processing. On ne peut souvent que calculer des approximations lors d’aggregations d’événements car on n’a pas toujours de garantie d’ordre.
Reprenons notre exemple de moyenne sur 10 secondes que nous avons vu précédemment. Vous recevez des événements entre T et T+10, vous calculez une moyenne sur ces événements. Que devez vous faire si vous recevez des événements du passé ? Dans le mauvais ordre ? Devons nous les ignorer ?
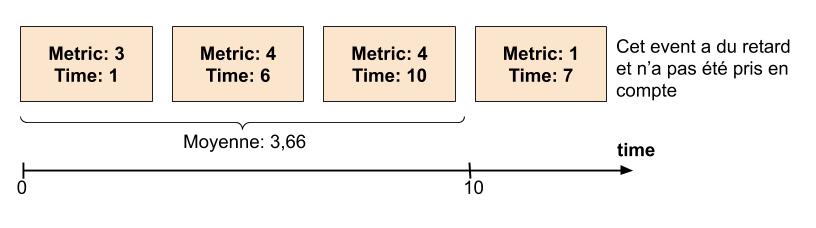
Mais cela n’est finalement pas grave. Vous pouvez calculer très rapidement une approximation qui sera suffisante pour la plupart des cas. Si je veux faire de l’aggregations sur des métriques venant de 100 machines, tant pis si je n’ai au final que 99 événements si cela me permet d’avoir très rapidement (en quelques secondes) une idée de la santé de la plateforme. Et si mes métriques arrivent en continu dans mon système, l’événement manquant pourra être pris en compte plus tard.
On pourrait imaginer également la mise en place d’un petit buffer de quelques secondes pour limiter ce problème.
Mais parfois, on a besoin d’avoir la garantie que notre calcul est correct. Je pense que le même outil de stream processing pourrait réaliser cela si implémenté correctement.
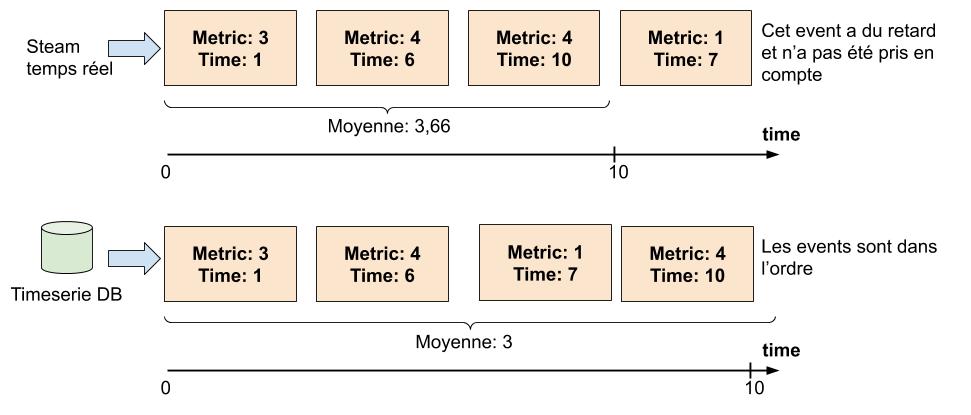
Imaginez si vous pouviez réinjecter dans un outil de stream processing des données venant de votre base de données timeseries.
On peut ici parler de continuous query. Si vous avez la capacité de ré-emettre les événements (ordonnés par timestamp) dans votre outil de stream processing, l’outil pourrait recalculer la valeur exacte de votre aggregation à partir de ces événements.
Cela demande à l’outil de gérer correctement les fenêtre de temps. Si l’on sait que les événements arrivent dans l’ordre, l’outil peut se contenter de se baser sur le temps de chaque événement pour faire avancer les différentes fenêtre de temps (et non exécuter un "tick" bêtement toutes les 10 secondes). Le temps n’a pas à avancer à la même vitesse dans la vraie vie et dans votre système de streaming, c’est ce stream d’événement qui doit être la source de vérité concernant le temps.
Cela a l’avantage de rendre l’outil prédictif: pour un même jeu de données en entrée, la sortie sera toujours la même. Reprendre un calcul est également facile vu qu’on sait où on s’est arrêté.
Et là: on a le meilleur des deux mondes:
- Mon outil de stream processing pour alerter rapidement (car par expérience, je veux souvent générer une alerte dès que je reçois un événement spécifique, je n’ai pas toujours besoin de faire des calculs pour générer mon alerte), déplacer mes métriques d’un système à un autre, faire des calculs approximatifs (parfois complexes) en temps réel sur mes métriques.
- Le même outil, pour faire du continuous query (à partir d’une ou plusieurs sources de données), tout en m’appuyant pourquoi pas sur les capacités de calculs de ma base de données timeserie pour pré-calculer certains trucs (et éviter de déplacer trop de données). Dans ce mode de fonctionnement, chaque query (et ses calculs associés) pourrait avancer "à son rythme" et elles n’auraient aucun effet de bords entre elles.
Et le tout avec un langage commun entre les deux modes.
Il m’arrive tous les 3 à 6 mois de commencer à écrire une version de l’outil décrit. Mais je ne suis jamais totalement satisfait donc je laisse tomber (et cela prend beaucoup de temps, que je n’ai pas forcément, j’ai déjà un certain nombre de projets à maintenir).
Ma dernière tentative date d’il y a 3 semaines où j’ai écrit un POC où des unités de calculs peuvent se représenter en structures de données Clojure (au format edn), avec un DSL simple pour écrire la configuration:
(-> (init {:name :foo
:stream? true
:by [:host]})
a/increment
(where :> 10)
(fixed-event-window 2)
mean
(debug!))
#:pipeline{:name "foo"
:stream? true
:by [:host]
:actions
[#:action{:name :increment}
#:action{:name :where
:params [:> 10]}
#:action{:name :fixed-event-window
:params [2]}
#:action{:name :mean}
#:action{:name :debug!}]}
Cette structure de données peut ensuite être transformée en stream exécutable. Cette structure de données peut également me servir de constructeur pour construire à la demande des unités de calculs, connectées à un serveur recevant des événements en mode streaming ou instanciées à la volée pour des continuous query.
Mais je n’ai malheureusement pas de temps à consacrer à ce projet actuellement.
Vector
Connaissez vous Vector ? Cet outil écrit en Rust permet notamment d’interconnecter différents systèmes entre eux. Vous le laissez scrap du Prometheus, consommer des logs, du Kafka… Et il se charge de transférer tout ça à des systèmes extérieurs (voir à d’autres instances de Vector).
Vous pouvez même réaliser certains calculs ou modifications à vos métriques et logs, et étendre le projet en lua (et donc théoriquement en fennel si vous aimez Clojure).
On peut aussi d’une certaine façon tester sa configuration (qui est écrite en toml, yaml ou json).
Interconnecter différents systèmes est, comme dit précédemment, une des forces de Riemann. D’ailleurs James Turnbull, un des mainteneurs de Riemann (qui avait aussi écrit un livre sur le sujet), travaille sans surprise sur Vector.
Comme indiqué dans sa documentation, Vector n’est pas fait pour faire du stream processing complexe. Mais je trouve le concept génial, et surtout on a enfin un outil bien conçu (du moins il semblerait après quelques tests rapides) pour scrape du Prometheus et renvoyer tout ça à d’autres systèmes.
Cela faisait longtemps que je n’avais pas été aussi enthousiaste sur un outil de monitoring. C’est peut être également une bonne excuse pour faire du Rust et contribuer un peu au projet. Et clairement si je pouvais avoir un Riemann-like compatible Vector pour les transformations complexes ce serait super cool.
Je prévois de tester Vector en détail sur mon infrastructure personnelle dans les mois à venir (et pourquoi pas faire un article dédié sur l’outil), et je pense que Vector peut devenir une des briques pour de nouveaux outils basés sur le push, et apporter la flexibilité que j’évoquais précédemment.