Prometheus possède une fonctionnalité peu connue appelée exemplars. Cette fonctionnalité permet notamment d’avoir du tracing basique intégré dans Prometheus.
Rappel du fonctionnement de Prometheus
Prometheus est un système de monitoring de type "pull": les applications exposent des métriques via HTTP et Prometheus va périodiquement aller les récupérer (on parle de scrape).
Voici par exemple ce qu’une application fictive pourrait exposer via HTTP (sur le chemin /metrics par exemple):
# HELP http_requests_duration_second Time to execute http requests
# TYPE http_requests_duration_second histogram
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.05"} 0
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.1"} 4
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.2"} 5
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.3"} 7
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.4"} 9
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.5"} 11
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.6"} 13
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.7"} 14
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.8"} 15
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.9"} 17
http_requests_duration_second_bucket{method="GET",path="/foo",le="+Inf"} 17
http_requests_duration_second_sum{method="GET",path="/foo"} 6.671887545999998
http_requests_duration_second_count{method="GET",path="/foo"} 17
Cette métrique de type histogramme représenter le temps d’exécution de requêtes HTTP (et également la nombre de ces requêtes via http_requests_duration_second_count).
Prenons quelques séries:
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.05"} 0: Il n’y a aucune (0) requête HTTP pour la méthodeGETet le path/fooayant un temps d’exécution inférieur à 0.05 seconde.http_requests_duration_second_bucket{method="GET",path="/foo",le="0.1"} 4: Il y a 4 requêtes HTTP ayant un temps d’exécution inférieur à 0.1 seconde, là aussi pourGET /foo.http_requests_duration_second_bucket{method="GET",path="/foo",le="0.9"} 17: Il y a 17 requêtes HTTP ayant un temps d’exécution inférieur à 0.9 secondes, là aussi pourGET /foo.
Bref, le client Prometheus de mon application va exposer pour chaque bucket (le label le sur la métrique) le nombre de requêtes dont le temps d’exécution est inférieur ou égal à la valeur de le.
Prometheus peut ensuite utiliser cette information pour calculer les quantiles (p99, p98, p75…).
Cela marche très bien mais Prometheus ne permet pas ici d’identifier quelles requêtes sont lentes. On a en effet seulement des métriques avec des labels généraux (method, path, le).
Prometheus n’est en effet pas fait pour l’exposition de métriques avec par exemple un ID de requête comme label de la métrique . Vous allez si vous faites cela générer de nombreuses métriques pour chaque appel HTTP à vos services et cela causera des problème de performances à Prometheus en plus de générer des métriques peu pertinentes.
J’ai d’ailleurs écrit un autre article sur le monitoring et sur les métriques essentielles à exposer sur une application et sur les bonnes pratiques associées que vous pouvez retrouver ici.
Une solution pour avoir ce niveau de détail serait d’implémenter une solution de tracing comme par exemple OpenTelemetry.
Il existe néanmoins une fonctionnalité un peu cachée (et récente) de Prometheuspermettant d’enrichir une métrique avec des informations (comme un ID requêtes HTTP) sans causer de problèmes au niveau de la cardinalité des métriques: les exemplars
Un exemple d’exemplar
Comme son nom l’indique, un exemplar va être une donnée associée à une métrique qui permettra d’identifier par exemple une requête (pour revenir à notre exemple de temps d’exécution de requêtes HTTP) faisant partie d’un bucket.
Voic par exemple ce que pourrait retourner Prometheus avec un exemplar associé à chaque série dans notre exemple précédent:
# HELP http_requests_duration_second Time to execute http requests
# TYPE http_requests_duration_second histogram
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.05"} 2 # {request_id="3339ae10-5a13-42a6-a577-a2627201ca5a"} 0.015179919 1.64444517479409e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.1"} 6 # {request_id="8d801ff2-9b1a-4be5-b845-86ba63ab29c4"} 0.08934196 1.6444451680623782e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.2"} 8 # {request_id="fdb9caed-d93e-49a5-bbaa-4da9e19b45e7"} 0.10628825 1.6444451700679393e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.3"} 13 # {request_id="7e86def7-a0af-4c11-8d16-d4b720fe2b03"} 0.28751035 1.644445173100252e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.4"} 17 # {request_id="d257baac-fe43-4147-8c08-95ced8e70d6a"} 0.356419323 1.644445177750266e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.5"} 25 # {request_id="68122c5c-f8cd-4244-940d-93b8a8be5e8f"} 0.48573844 1.6444451796056514e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.6"} 29 # {request_id="d73c28e2-e745-48b2-8360-b122fb7419f1"} 0.541845484 1.6444451753361151e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.7"} 31 # {request_id="6630ac51-ee27-49d1-8074-e8fd0255623d"} 0.631918345 1.64444517911979e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.8"} 34 # {request_id="b1d038b8-cfec-4a1f-9ca0-e3587457ac2f"} 0.73743838 1.6444451784877608e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.9"} 38 # {request_id="1abb575c-17a2-4046-a0a5-f60b35f8c560"} 0.831036906 1.6444451769639566e+09
http_requests_duration_second_bucket{method="GET",path="/foo",le="+Inf"} 39 # {request_id="c92dce8c-0be7-4f3f-a6cc-89e8e83f7e28"} 0.947113356 1.644445172812602e+09
http_requests_duration_second_sum{method="GET",path="/foo"} 16.99887299
http_requests_duration_second_count{method="GET",path="/foo"} 39
Cela rassemble à avant mais on voit par exemple un suffixe ajouté à nos série. Prenoms un exemple.
http_requests_duration_second_bucket{method="GET",path="/foo",le="0.9"} 38 # {request_id="1abb575c-17a2-4046-a0a5-f60b35f8c560"} 0.831036906 1.6444451769639566e+09: la première partie de cette ligne correspond comment avant à notre série: nous avons 38 requêtes s’exécutant en moins de 0.9 seconde.
Mon exemplar vient après: # {request_id="1abb575c-17a2-4046-a0a5-f60b35f8c560"} 0.831036906 1.6444451769639566e+09. Prometheus me dit ici que la requête ayant comme ID 1abb575c-17a2-4046-a0a5-f60b35f8c560 s’est exécutée en 0.831036906 secondes au timestamp 1.6444451769639566e+09.
Super ! Je peux maintenant chercher par exemple dans mes logs cet ID de requête pour voir exactement à quoi elle correspond (utilisateur, paramètres…).
Les exemplars ne remplacent pas un vrai système de tracing (qui est distribué) mais peuvent donc nous aider en nous donnant quelques 'exemples" de requêtes pour chaque série.
Il est important de comprendre que vous ne pouvez avoir qu’un seul exemplar par série. Si vous en ajoutez un nouveau dans votre code pour une série donnée il viendra remplacer l’ancien.
OpenMetrics
Les clients Prometheus comme le client Golang n’exposent pas par défaut les exemplars même si vous les configurez dans le code. Vous devez pour les faire marcher réaliser plusieurs actions:
- Activer le format
OpenMetricsdans le client Prometheus avecEnableOpenMetrics: true(un exemple de code se trouve à la fin de cet article). Attention, Prometheus est en cours de transition vers OpenMetrics et même si le format est quasiment identique au format Prometheus il vaut mieux bien relire la documentation sur ce format pour éviter les surprises. - Passer le header
Accept: application/openmetrics-textpour forcer Prometheus à retourner les métriques au format OpenMetrics (par exemplecurl -H 'Accept: application/openmetrics-text' localhost:9001/metrics). - Démarrer Prometheus avec l’option
--enable-feature=exemplar-storage.
Intégration Grafana
Grafana supporte les exemplars !
Vous pouvez simplement les activer dans la datasource Prometheus. Vous verrez ensuite des points représentant vos exemplars sur vos dashboards Grafana et vous n’avez qu’à glisser votre souris dessus pour voir ses informations:
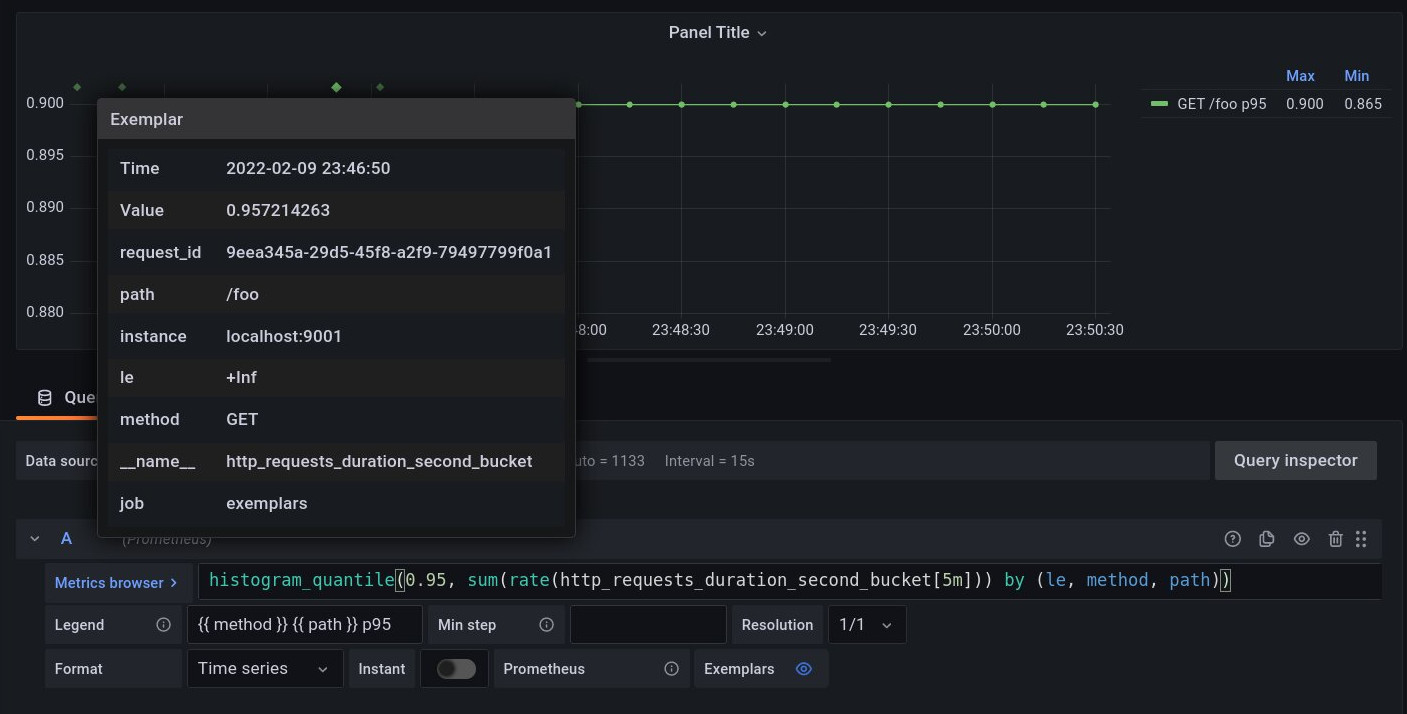
Vous pourrez comme cela très rapidement visualiser les requêtes problématiques.
Un exemple de code créant des exemplars
Ce n’est pas le code le plus joli qui soit mais le but ici est vraiment de présenter la fonctionnalité:
package main
import (
"github.com/google/uuid"
prom "github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"fmt"
"math/rand"
"net/http"
"time"
)
func main() {
reg := prom.NewRegistry()
buckets := []float64{
0.05, 0.1, 0.2, 0.3, 0.4, 0.5,
0.6, 0.7, 0.8, 0.9}
http.Handle("/metrics", promhttp.HandlerFor(reg, promhttp.HandlerOpts{EnableOpenMetrics: true}))
reqHistogram := prom.NewHistogramVec(
prom.HistogramOpts{
Name: "http_requests_duration_second",
Help: "Time to execute http requests",
Buckets: buckets,
},
[]string{"method", "path"})
reg.Register(reqHistogram)
go func() {
for i := 0; i < 100; i++ {
reqID := uuid.NewString()
start := time.Now()
time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond)
duration := time.Since(start)
fmt.Printf("request %s took %dms\n", reqID, int64(duration/time.Millisecond))
labels := prom.Labels{"method": "GET", "path": "/foo"}
// we cast the histogram into a ExemplarObserver in order to call ObserveWithExemplar on it
reqHistogram.With(labels).(prom.ExemplarObserver).ObserveWithExemplar(duration.Seconds(), prom.Labels{"request_id": reqID})
}
}()
http.ListenAndServe(":9001", nil)
}
Comme vous le voyez je crée ici un exemplar à chaque ajout de valeur dans mon histogramme.
Je n’ai encore jamais utilisé cette feature en production, je ne connais donc pas l’impact des exemplars sur les performances du client Golang ou de Prometheus.
Conclusion
Les exemplars sont une fonctionnalité très intéressante de Prometheus qui je pense se démocratisera. Cela ne remplace pas comme dit précédemment un vrai système de tracing mais le complète. Si vous êtes utilisateur d’OpenTelemetry il peut par exemple être intéressant d’intégrer la traceID comme exemplar dans vos métriques Prometheus.